In industrial automation, when it is required to communicate data from OT to IT or higher-level cloud services, there are various types of communication protocols used in it. One such model, which is widely used, is a publisher-subscriber model.
In recent times, it has taken industrial automation communication to such an advanced and reliable level with rapid speed that data transfer has become efficient nowadays. So, today’s engineers must understand the importance of this communication model. In this post, we will see the publisher-subscriber model with its proper concept understanding.
What is the core concept of the publisher-subscriber model?
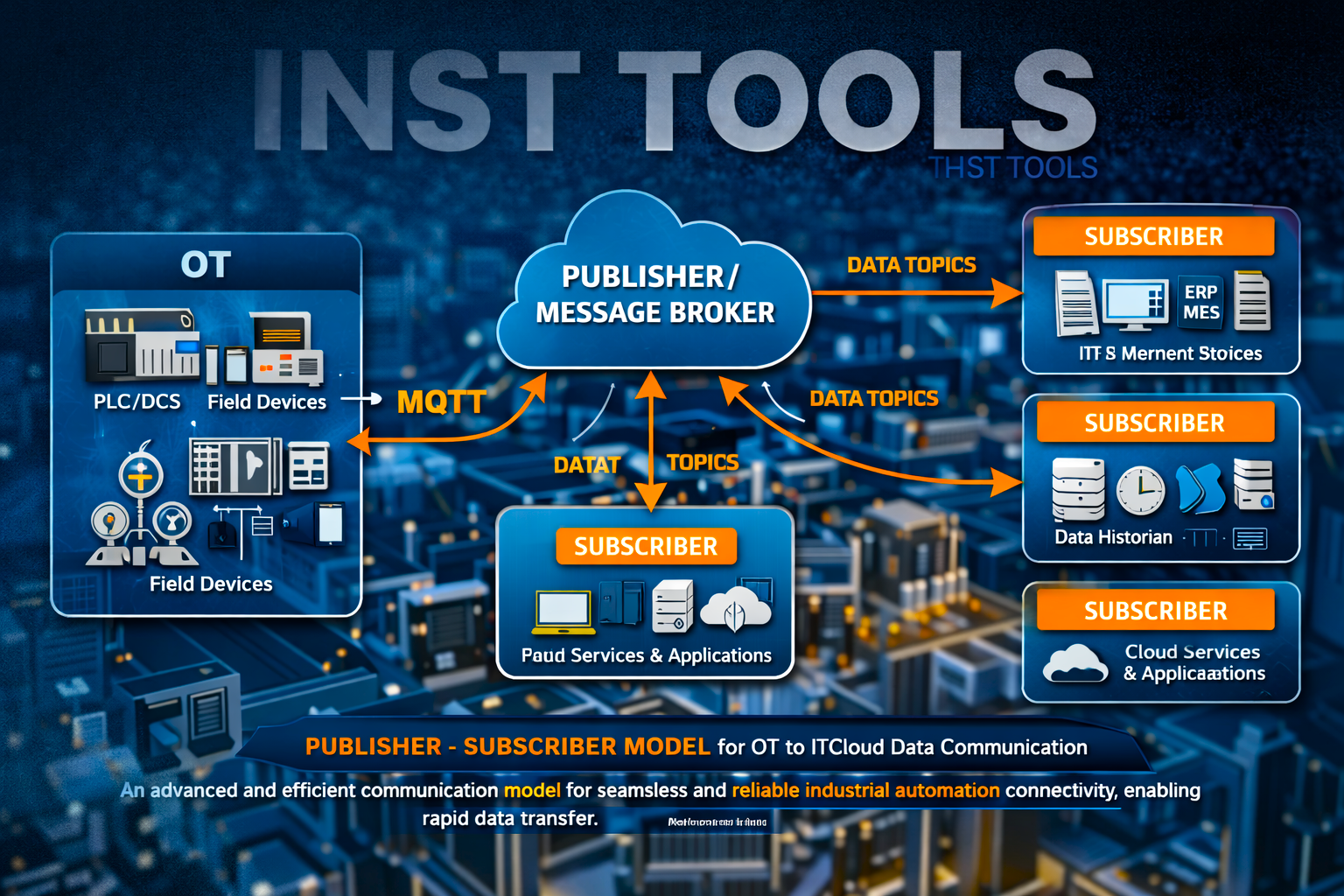
Let us first understand the core concept and how the basic model works. The publish-subscribe model is an asynchronous messaging pattern (meaning senders and receivers exchange messages without waiting for each other to be online or ready at the same time) that separates message producers or publishers from the consumers or subscribers.
Publishers generate messages like events, data updates, alarms, telemetry, and logs, and the subscribers get these specific message categories by expressing interest in them. But they communicate with each other via brokers or message servers. So, the publishers do not know who the subscribers are, and the subscribers do not know who the publishers are. Without a broker, there will be no communication.
In an asynchronous pub/sub system, each component works independently, so the system continues functioning even if one part goes down.
- If the publisher is offline, no new messages are generated, but subscribers remain active and they simply wait for the next message when the publisher returns. When the publisher comes back online, it resumes publishing normally.
- If the broker goes down, the entire flow temporarily stops because it is the central hub; publishers cannot publish, and subscribers cannot receive. A broker cannot store messages while it is offline; it has no ability to receive or process anything during downtime. What actually happens is that any messages the broker had already received before it went down can be safely stored if the broker uses persistent storage (for example, disk-based logs, queues, or retained sessions). These stored messages are preserved and available when the broker restarts. However, during the period when the broker is offline, all new messages published by devices or applications simply cannot reach it, so those messages are lost unless the publisher itself has its own buffering mechanism. In short, persistence protects only the messages that arrived before the failure, not the ones sent during the broker’s downtime.
- If the subscriber goes offline, the publisher still keeps sending messages normally because it doesn’t wait for the receivers. The broker may store those messages (if retention or appropriate QoS is enabled), and when the subscriber comes back, it can either retrieve all missed messages or start fresh, depending on the configuration.
Decoupling types in the publisher-subscriber model
As we saw, a publisher and subscriber are separated or decoupled by a broker. So, there are three types of decoupling in this model. Let us understand each one of them.
Space decoupling
The space decoupling provides a physical or location independence. The publisher does not know the subscriber’s IP, hostname, or how many devices are there on the other side. The same goes with the subscriber, who does not have publisher details. They both know only the same topic name (will discuss later in the post) and the broker name. It thus guarantees that the components don’t need to know each other for communication.
Time decoupling
The time decoupling provides a time independence. Both the publisher and subscriber are not required to be online at the same time, or in short, they can work even if one is offline. They depend on the broker to support message storage for this facility, so that whenever one goes offline and comes back online, the last saved messages will be delivered. It thus guarantees that the messages flow even if the subscriber is offline.
Synchronisation decoupling
The synchronisation decoupling removes the requirement for both the sides to operate at the same speed. The publisher sends instantly and continues it’s work without waiting. The subscriber may be slow, busy, overloaded or processing later. The broker manages the delay or buffering. It thus guarantees that the messages flow even if the subscriber is slow.
In a Pub/Sub application, all three decoupling types – space, time, and synchronization can work together, and in most modern systems, they do.
- Space decoupling lets publishers and subscribers work without knowing each other.
- Time decoupling allows them to be offline at different times.
- Synchronization decoupling ensures publishers don’t wait for subscribers.
While it is possible to design a system using only one or two of these, the full power and flexibility of pub/sub is achieved when all three types are used together.
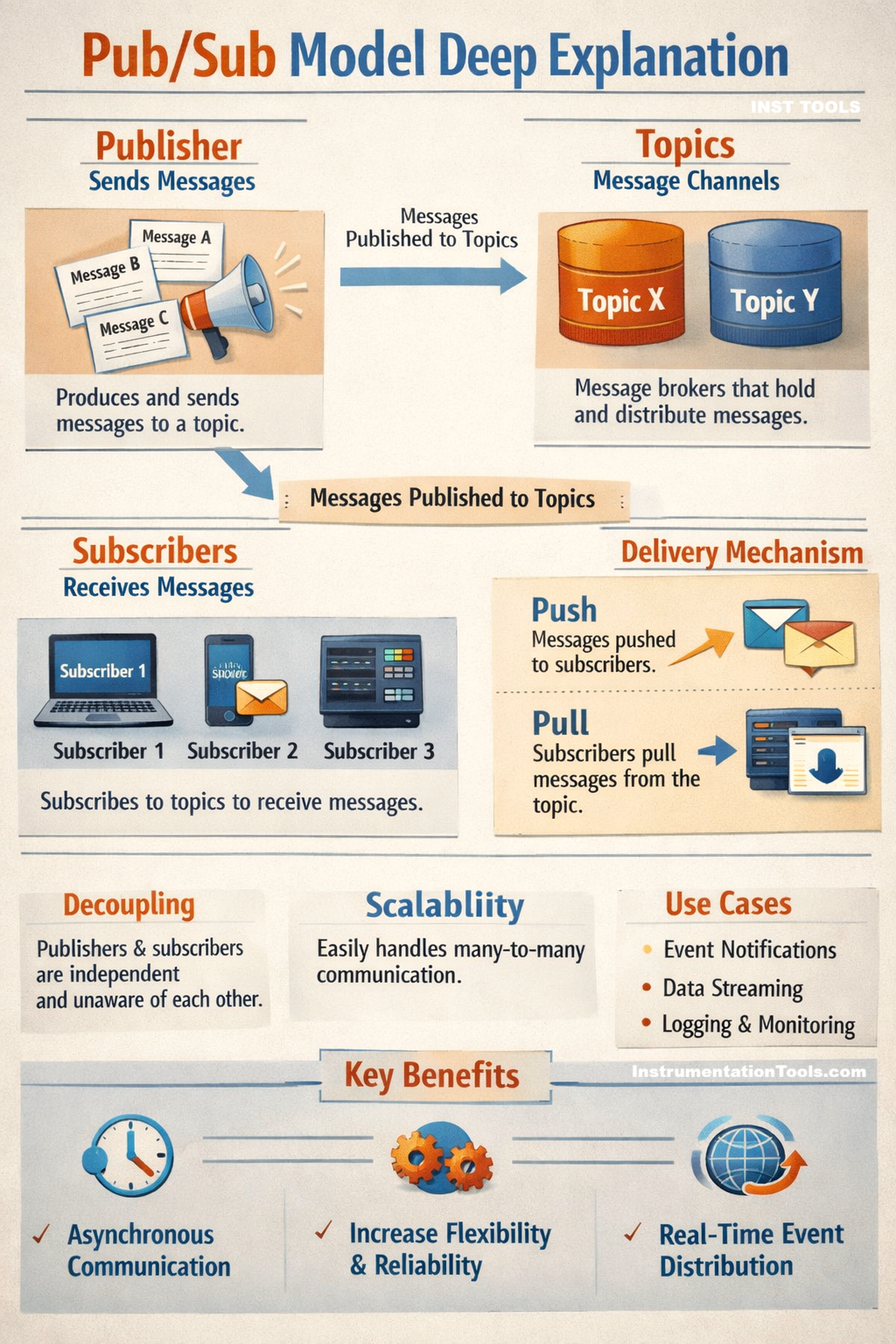
The role of a broker in the publisher-subscriber model
As we saw earlier, the broker is the heart of the pub/sub model. If there is no broker, then no communication will happen. Before understanding it, let us first understand the concept of topic name. The topic name is managed by the broker. A topic name is simply a label or path that the publisher uses to categorize the message, and that subscribers use to choose what type of data they want to receive.
In simple terms, a topic name is like a channel name or a folder name where messages are placed. Publishers send messages to that topic, and subscribers read messages from that topic. So, the whole thing of managing messages with this topic name is done by the broker. Each message is tagged with a topic name, so subscribers can choose what to receive.
The broker sends messages to subscribers using either push (broker actively sends) or pull (subscriber fetches) methods. As discussed earlier, it can also store messages on it’s server and help in retrieving it if the publisher or subscriber goes offline anytime and comes online again. The broker is so efficient that it can connect with multiple subscribers easily and reliably. It thus ensures that the messages are delivered according to defined QoS levels (at-most-once, at-least-once and exactly-once, which we will see later in the post). The broker also handles retries, acknowledgments, and error recovery.
Pub/sub flow in industrial communication
1. Publisher Creates a Payload and Sends It to a Topic
In the publisher subscriber model, the term which is used to describe a message is called a payload, which is the actual data being sent. This payload can be JSON, binary, key-value pairs, Sparkplug B format, or any schema defined by the system. As you already know the topic name which is nothing but the channel where the messages will be sent, the payload here is sent to this topic (for example: line1/temp, robot/status, plant1/pack_count).
2. Broker Receives the Payload and Organizes It by Topic
Once the broker receives the payload, it’s job is now to handle this data. Each topic name with the corresponding payload is stored in the internal memory buffer or queue system. In this way, the broker has now got all the topic names with their payloads and managed in it’s buffer. It does not modify the payload but safely holds it, validates it, and prepares it for delivery.
3. Subscribers Register Their Interest in a Topic
Now that both the broker and publisher have done their work, then comes the role of the subscriber. Subscriber only subscribes for the topic name to get the payload. So all the messages with the demanded topic name are registered to that subscriber by the broker. Subscribers may also define QoS level, raw/decoded format, or retained message behavior depending on the protocol.
4. Broker Distributes the Payload to All Subscribers
When new data arrives, the broker checks its subscription list, finds all clients that subscribed to the topic, and sends them the same payload. One payload can therefore reach many devices simultaneously, making the system highly efficient. The broker also ensures reliable delivery using QoS rules; for example, message retry, acknowledgment, or retained messages for offline subscribers.
If a subscriber reconnects after being offline, it can still receive the latest payload depending on settings like persistent sessions or retained messages. This distribution step is the core advantage of Pub/Sub: a single publish event fans out to multiple consumers automatically.
One thing to note is that out of three QoS levels of 0, 1 and 2, subscribers also send acknowledgement to the publisher in 1 and 2, which we will see later.
Quality of Service (QoS)
Now, let us see the QoS levels as required earlier for understanding:
Quality of Service (QoS) in a pub/sub system defines how safely a message is delivered from the publisher to the subscriber. Higher QoS means better reliability but more network usage.
QoS 0 – Message may be lost
In QoS 0, the publisher sends the message and does not check whether it reached the subscriber. There is no confirmation and no retry. If the network is busy or broken, the message can be lost. This method is very fast and lightweight. It is used when data is sent frequently and losing some messages is acceptable, such as temperature values updating every second.
QoS 1 – Message will arrive, but maybe more than once
In QoS 1, the publisher waits for confirmation that the message was received. If no confirmation comes, the message is sent again. This ensures the message is delivered at least once, but sometimes the same message can be received twice. Because of this, the subscriber must be able to handle duplicate messages. This level is commonly used for alarms, machine status, or events where missing data is not acceptable.
QoS 2 – Message arrives exactly once
QoS 2 is the safest level. It ensures that the message is delivered one time only, with no loss and no duplication. This is done using multiple confirmation steps between the publisher, broker, and subscriber. Because of this, it is slower and uses more network resources. QoS 2 is used for critical operations such as control commands or configuration changes where accuracy is very important.