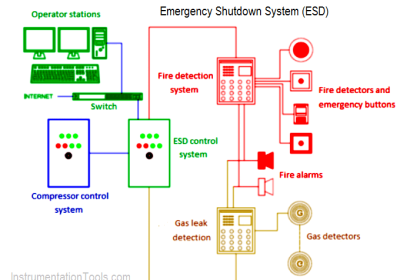
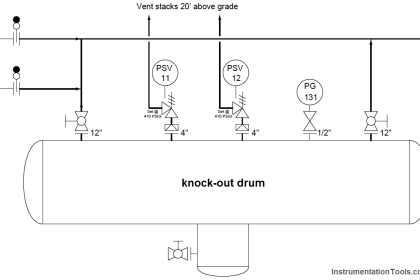
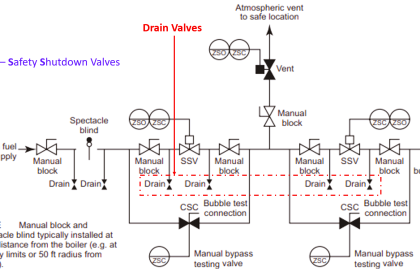
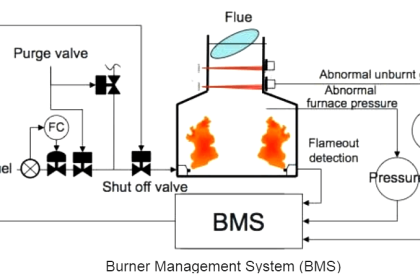
A reliability enhancing technique related to preventive maintenance of critical instruments and functions, but generally not as expensive as component replacement, is periodic testing of component and system function.
Regular “proof testing” of critical components enhances the MTBF of a system for two different reasons:
- Early detection of developing problems
- Regular “exercise” of components
First, proof testing may reveal weaknesses developing in components, indicating the need for replacement in the near future.
An analogy to this is visiting a doctor to get a comprehensive exam – if this is done regularly, potentially fatal conditions may be detected early and crises averted.
The second way proof testing increases system reliability is by realizing the beneficial effects of regular function. The performance of many component and system types tends to degrade after prolonged periods of inactivity.
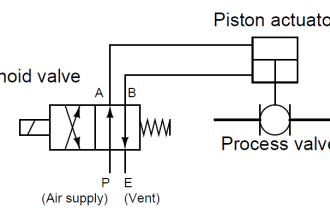
This tendency is most prevalent in mechanical systems, but holds true for some electrical components and systems as well. Solenoid valves, for instance, may become “stuck” in place if not cycled for long periods of time.
Bearings may corrode and seize in place if left immobile. Both primary- and secondary-cell batteries are well known for their tendency to fail after prolonged periods of non-use.
Regular cycling of such components actually enhances their reliability, decreasing the probability of a “stagnation” related failure well before the rated useful life has elapsed.
Proof Testing of Safety Instrumented Systems

An important part of any proof-testing program is to ensure a ready stock of spare components is kept on hand in the event proof-testing reveals a failed component.
Proof testing is of little value if the failed component cannot be immediately repaired or replaced, and so these warehoused components should be configured (or be easily configurable) with the exact parameters necessary for immediate installation.
A common tendency in business is to focus attention on the engineering and installation of process and control systems, but neglect to invest in the support materials and infrastructure to keep those systems in excellent condition. High-reliability systems have special needs, and this is one of them.
Methods of Proof Testing
The most direct method of testing a critical system is to stimulate it to its range limits and observe its reaction. For a process transmitter, this sort of test usually takes the form of a full-range calibration check.
For a controller, proof testing would consist of driving all input signals through their respective ranges in all combinations to check for the appropriate output response(s).
For a final control element (such as a control valve), this requires full stroking of the element, coupled with physical leakage tests (or other assessments) to ensure the element is having the intended effect on the process.
An obvious challenge to proof testing is how to perform such comprehensive tests without disrupting the process in which it functions.
Proof-testing an out-of-service instrument is a simple matter, but proof-testing an instrument installed in a working system is something else entirely.
How can transmitters, controllers, and final control elements be manipulated through their entire operating ranges without actually disturbing (best case) or halting (worst case) the process?
Even if all tests may be performed at the required intervals during shut-down periods, the tests are not as realistic as they could be with the process operating at typical pressures and temperatures.
Proof-testing components during actual “run” conditions is the most realistic way to assess their readiness.
One way to proof-test critical instruments with minimal impact to the continued operation of a process is to perform the tests on only some components, not all.
For instance, it is a relatively simple matter to take a transmitter out of service in an operating process to check its response to stimuli: simply place the controller in manual mode and let a human operator control the process manually while an instrument technician tests the transmitter.
While this strategy admittedly is not comprehensive, at least proof-testing some of the instruments is better than proof-testing none of them.
Another method of proof-testing is to “test to shutdown:” choose a time when operations personnel plan on shutting the process down anyway, then use that time as an opportunity to proof-test one or more critical component(s) necessary for the system to run. This method enjoys the greatest degree of realism, while avoiding the inconvenience and expense of an unnecessary process interruption.
Yet another method to perform proof tests on critical instrumentation is to accelerate the speed of the testing stimuli so that the final control elements will not react fully enough to actually disrupt the process, but yet will adequately assess the responsiveness of all (or most) of the components in question.
The nuclear power industry sometimes uses this proof-test technique, by applying high speed pulse signals to safety shutdown sensors in order to test the proper operation of shutdown logic, without actually shutting the reactor down.
The test consists of injecting short-duration pulse signals at the sensor level, then monitoring the output of the shutdown logic to ensure consequent pulse signals are sent to the shutdown device(s).
Various chemical and petroleum industries apply a similar proof-testing technique to safety valves called partial stroke testing, whereby the valve is stroked only part of its travel: enough to ensure the valve is capable of adequate motion without closing (or opening, depending on the valve function) enough to actually disrupt the process.
Redundant systems offer unique benefits and challenges to component proof-testing. The benefit of a redundant system in this regard is that any one redundant component may be removed from service for testing without any special action by operations personnel.
Unlike a “simplex” system where removal of an instrument requires a human operator to manually take over control during the duration of the test, the “backup” components of a redundant system should do this automatically, theoretically making the test much easier to conduct.
However, the challenge of doing this is the fact that the portion of the system responsible for ensuring seamless transition in the event of a failure is in fact a component liable to failure itself.
The only way to test this component is to actually disable one (or more, in highly redundant configurations) of the redundant components to see whether or not the remaining component(s) perform their redundant roles.
So, proof-testing a redundant system harbors no danger if all components of the system are good, but risks process disruption if there happens to be an undetected fault.
Let us return to our triplicate level transmitter system once again to explore these concepts. Suppose we wished to perform a proof-test of the pressure-based level transmitter.
Being one of three transmitters measuring liquid level in this vessel, we should be able to remove it from service with no preparation (other than notifying operations personnel of the test, and of the potential consequences)
since the selector function should automatically de-select the disabled transmitter and continue measuring the process via the remaining two transmitters. If the proof-testing is successful, it proves not only that the transmitter works, but also that the selector function adequately performed its task in “backing up” the tested transmitter while it was removed.
However, if the selector function happened to be failed when we disable the one level transmitter for proof-testing, the selected process level signal could register a faulty value instead of switching to the two remaining transmitters’ signals.
This might disrupt the process, especially if the selected level signal went to a control loop or to an automatic shutdown system. We could, of course, proceed with the utmost caution by having operations personnel place the control system in “manual” mode while we remove that one transmitter from service, just in case the redundancy does not function as designed.
Doing so, however, fails to fully test the system’s redundancy, since by placing the system in manual mode before the test we do not allow the redundant logic to fully function as it would be expected to in the event of an actual instrument failure.
Regular proof-testing is an essential activity to realize optimum reliability for any critical system.
However, in all proof-testing we are faced with a choice: either test the components to their fullest degree, in their normal operating modes, and risk (or perhaps guarantee) a process disruption; or perform a test that is less than comprehensive, but with less (or no) risk of process disruption.
In the vast majority of cases, the latter option is chosen simply due to the costs associated with process disruption.
Our challenge as instrumentation professionals is to formulate proof tests that are as comprehensive as possible while being the least disruptive to the process we are trying to regulate.