A rapidly growing SCADA database is a common challenge in industrial automation systems and can significantly impact overall performance if not managed properly. As process data, alarms, and events are continuously logged, the database can quickly become overloaded, leading to slower screen updates, delayed trends, and increased response time for operators.
SCADA Database Growing Too Fast
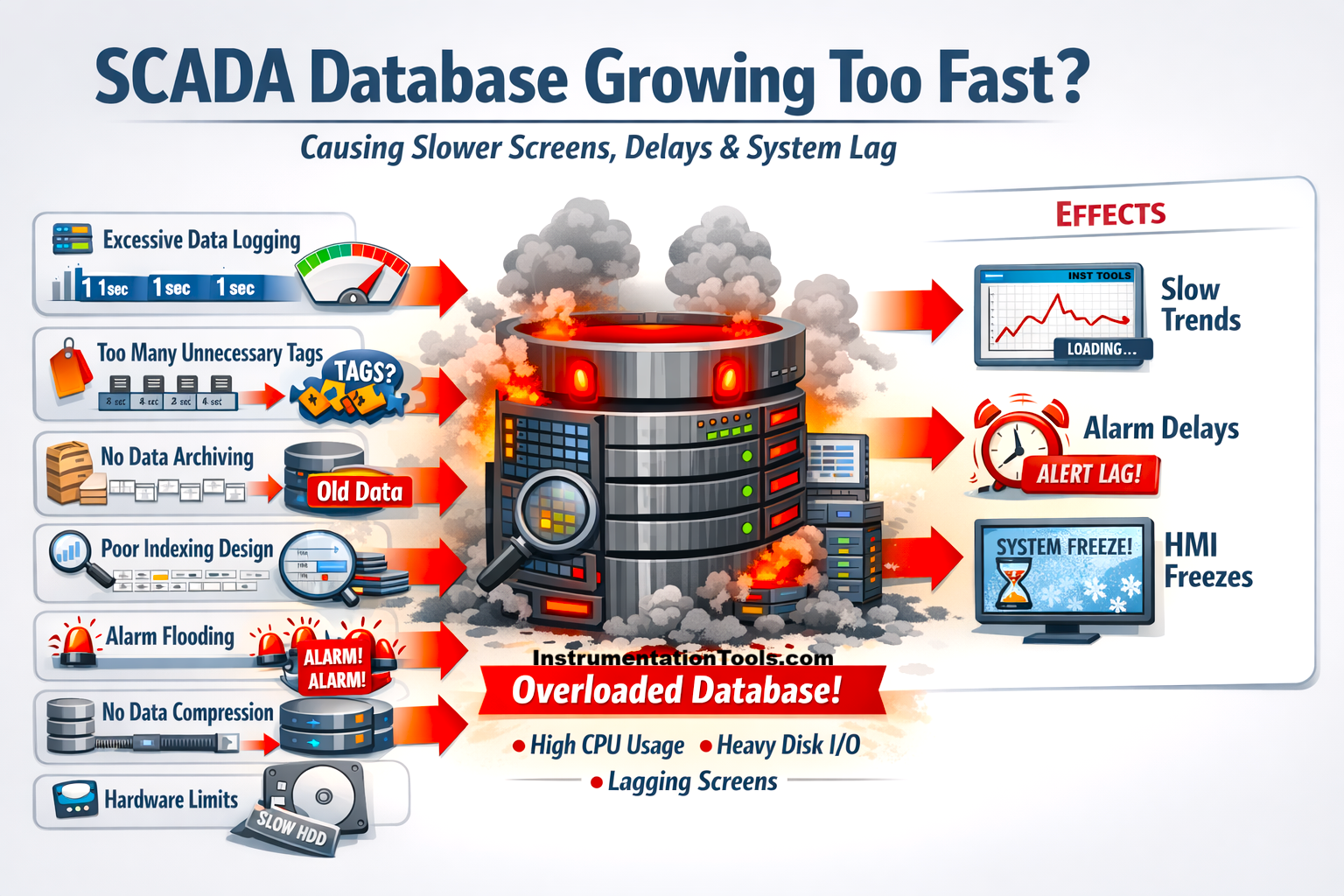
This issue is often not due to a single cause but a combination of excessive data logging, poor data management practices, and a lack of optimization strategies. Understanding how database growth affects system performance is essential for ensuring reliable operation, efficient data retrieval, and long-term stability of the SCADA system.
Excessive data logging (over-sampling)
One of the most common reasons for rapid SCADA database growth is logging data at a much higher frequency than actually required. In many systems, tags are configured to store values at fixed short intervals, such as every 1 second, regardless of whether the process value has changed or not. This results in a massive amount of redundant data being stored over time.
In real industrial scenarios, not all parameters need high-speed logging. For example, temperature, level, or pressure signals typically change slowly, yet they are often logged at the same rate as fast-changing signals like flow or motor speed. This mismatch leads to unnecessary data accumulation without adding any real analytical value.
The practical impact is significant: the database size increases rapidly, disk read/write operations become heavier, and retrieving historical data for trends or reports takes longer. Over time, this directly affects SCADA performance, causing lag in operator screens and delays in decision-making.
Storing unnecessary tags
Another major contributor to rapid SCADA database growth is the practice of storing a large number of unnecessary or low-value tags. In many projects, engineers tend to log almost every available signal from the PLC, including internal calculation tags, intermediate logic values, diagnostic bits, and even temporary or testing variables. This usually happens during commissioning or development phases, where additional tags are enabled for debugging purposes but are never removed later.
Over time, this leads to a situation where the database is filled with data that has little to no operational or analytical importance. While each individual tag may not seem significant, the cumulative effect of hundreds or thousands of such tags being logged continuously results in a massive increase in stored data volume.
No data archiving strategy
A significant reason for uncontrolled SCADA database growth is the absence of a proper data archiving or retention strategy. In many systems, historical data such as process values, alarms, and events are continuously stored in the same primary database without any mechanism to move or segregate older records. As a result, the database keeps expanding indefinitely over months and years of operation.
In real industrial environments, SCADA systems run 24/7, generating data every second. Without archiving, even a moderately sized plant can accumulate millions of records in a short period. Over time, the database tables become extremely large, making them difficult to manage efficiently.
Poor indexing and database design
Another critical factor contributing to slow SCADA performance is poor database structuring and a lack of proper indexing. As data grows, the way it is organized inside the database becomes extremely important. If tables storing historical data are not properly indexed, especially on key fields like timestamp, tag name, or event type, the database struggles to retrieve information efficiently.
In practical scenarios, SCADA systems frequently query data for trends, alarms, and reports based on time ranges or specific tags. Without indexing, the database is forced to perform full table scans, meaning it checks every record in the table to find the required data. When tables contain millions of rows, this process becomes very slow and resource-intensive.
Alarm & event flooding
Alarm and event flooding is another major contributor to rapid database growth and system slowdown. In many industrial systems, certain signals tend to fluctuate rapidly due to unstable process conditions, noise, or improper configuration. This can cause alarms to repeatedly trigger and clear within a short span of time, generating a large number of entries in the alarm and event history tables.
In real-world scenarios, a single chattering signal can create hundreds or even thousands of alarm records within minutes. When multiple such signals exist, the volume of alarm and event data increases dramatically. Since SCADA systems are designed to log every alarm occurrence with timestamps and status changes, this continuous flood quickly fills up the database.
Hardware & storage limitations
Apart from configuration and data handling practices, physical hardware limitations also play a crucial role in SCADA database performance. As the database grows rapidly, the demand for storage devices, memory, and processing power increases significantly. If the underlying hardware is not capable of handling this load, system performance starts to degrade.
In real-world setups, many SCADA systems initially run on standard hard disk drives (HDDs) or shared servers. As data accumulates, disk read/write operations become slower, especially when large volumes of historical data are being continuously written and accessed simultaneously. High disk latency directly affects how quickly the database can respond to queries. Additionally, limited RAM and CPU resources can struggle to handle large datasets, complex queries, and multiple user requests at the same time.
In this way, we saw how the SCADA database keeps growing too fast and slows down the system.